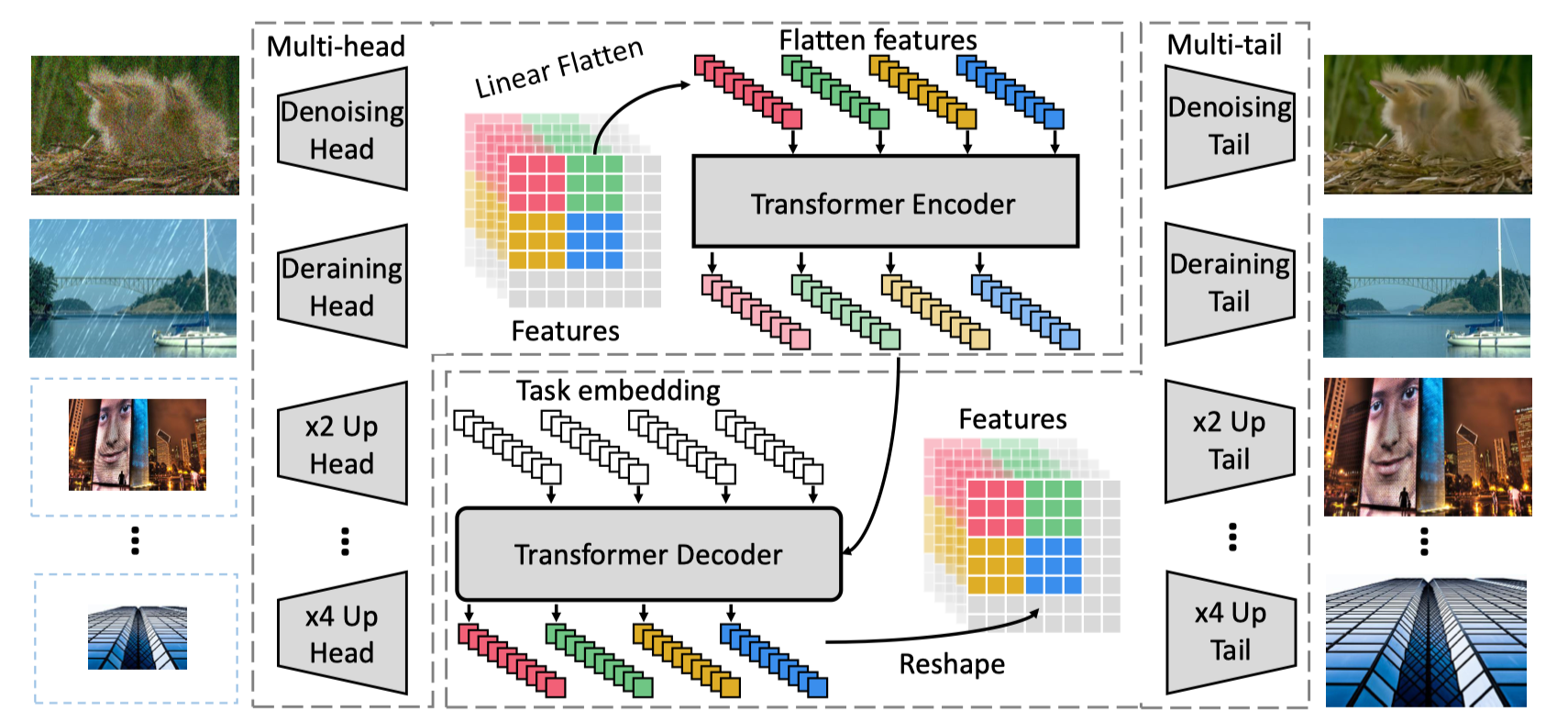
Chen et al. - 2021 - Pre-Trained Image Processing Transformer

2022/08/24
posted in
笔记
#Transformer